Key Takeaways
1. The Philips Hue AI assistant is now rolling out to select users in the Benelux area (Belgium, Netherlands, Luxembourg).
2. Currently, the assistant is only available for English-speaking customers.
3. The AI assistant is free and located in the Home tab of the Philips Hue app, integrating with the existing search function.
4. Users can create custom lighting scenes using voice or text commands and provide feedback on AI suggestions.
5. Philips Hue plans to expand the AI assistant’s availability to other countries soon but has not specified a timeline.
The Philips Hue AI assistant has started to roll out to select users. This feature was initially revealed in January 2025, and an icon related to it briefly appeared in version 5.38.1 of the Philips Hue app for iOS.
Availability in Benelux
Philips Hue has confirmed through its social media that the AI assistant is currently accessible to customers in the Benelux area, which includes Belgium, the Netherlands, and Luxembourg. At this point, it is only available for customers who speak English.
Features of the Assistant
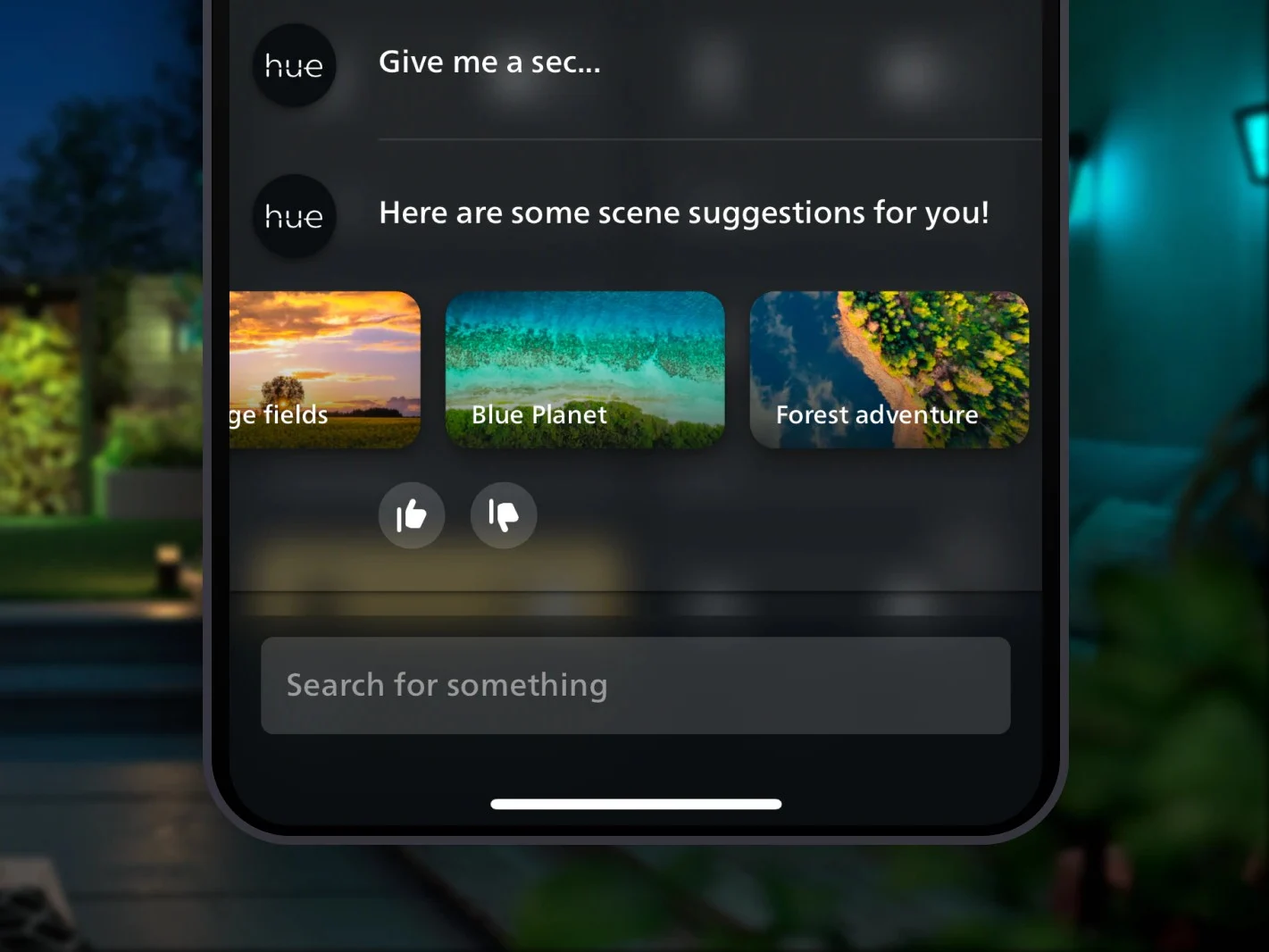
The Philips Hue AI-powered assistant is free to use and can be found in the Home tab, where it merges with the existing search function. This new feature lets users create lighting effects that match their mood or activities. It can locate existing lighting scenes or develop custom scenes using voice or text commands. Some example commands are “Set good makeup lighting”, “What’s the best scene for spring?”, and “Which scene should I set for dinner?”.
Users have the option to give feedback on the AI’s suggestions through like and dislike buttons. Additionally, the company advises users to “use responsibly” and cautions against sharing any personal data. In a recent post on its Instagram, Philips Hue mentioned that they plan to expand availability to other countries “soon”. However, they haven’t provided a specific timeline for this rollout.
Source:
Link