Key Takeaways
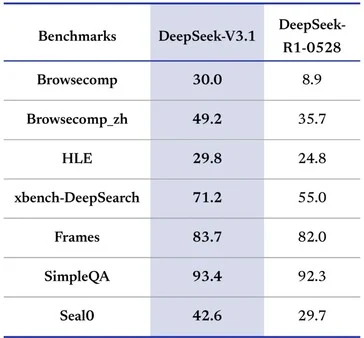
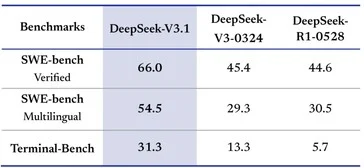
1. Advanced AI Transcription: The Plaud Note Pro can transcribe recordings into 112 languages and create summaries, utilizing various AI models like GPT-5.
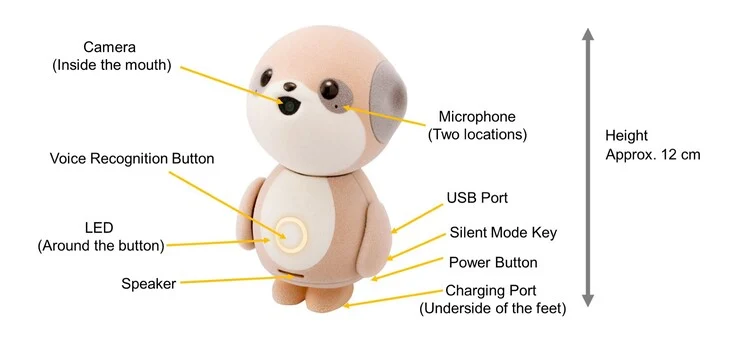
2. User-Friendly Features: It includes a button for marking important moments and uses AI beamforming microphones to reduce background noise, making it suitable for various recording contexts.
3. Design and Portability: The device is sleek, magnetically attachable to phones, offers a bright OLED screen, and provides up to 30 hours of battery life.
4. Compliance and Data Management: It adheres to HIPAA and GDPR regulations, allowing collected data to be shared, exported, or queried for efficient information retrieval.
5. Pricing and Availability: The Plaud Note Pro is priced at $179 with various subscription plans for transcription minutes, and is currently available for pre-order.
Plaud has introduced the Plaud Note Pro, which is a new version of its AI-driven note-taking gadget.
Advanced AI Transcription
Plaud Intelligence is capable of automatically turning recordings into any of 112 different languages, even including specific terms used in various industries. It can also create summaries by interpreting the information in multiple ways. Users can attach images and text to these recordings, enhancing understanding from various perspectives, as stated by the company. The AI utilizes a variety of available AI LLM models, such as GPT-5, Claude Sonnet 4, and Gemini 2.5 Pro.
Key Features for Enhanced Usability
A button on the device allows users to mark significant moments during calls, meetings, or lectures, while AI beamforming microphones work to minimize background noise during recordings, according to the company. This device can also function like a voice recorder, capturing details about sales, patient notes, and personal reflections. All the data collected can be shared, exported, or queried using Plaud Intelligence for answering questions from meetings. Importantly, the device complies with HIPAA and GDPR regulations.
Design and Specifications
This sleek device can be magnetically attached to phones, including Apple iPhones with MagSafe, or it can be used independently. The 0.95-inch OLED screen offers 600 nits brightness and is safeguarded by Gorilla Glass, displaying essential information like battery life and device status. Users can enjoy up to 30 hours of operation on a single charge. The AI recorder is just 0.12 in. (2.99 mm) thick and weighs 1.1 oz. (30 g).
The Plaud Note Pro is priced at $179 and is now open for pre-order. With the free plan, users get 300 minutes of transcription monthly. The Pro plan costs $99.99 per year and includes 1,200 minutes each month, while the Unlimited plan is available for $239.99 annually, offering unlimited transcription. For those eager to use the product before the official release, Plaud’s other offerings can be found in the company’s Amazon store.
Source:
Link