

Key Takeaways
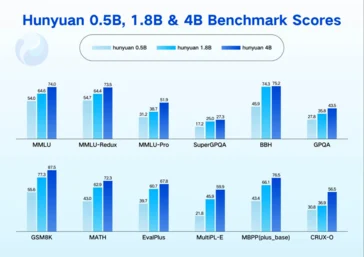
1. Tencent has launched new compact Hunyuan models with 0.5 billion, 1.8 billion, 4 billion, and 7 billion parameters, optimized for low-power devices and edge deployment.
2. These models excel in language comprehension, math, and reasoning tasks, thanks to their innovative “fusion reasoning” architecture.
3. They feature a native 256K token context window, enabling them to process large amounts of text in a single inference, useful for applications like meeting transcript analysis.
4. The models are compatible with popular inference frameworks and have early support from companies like Arm, Qualcomm, Intel, and MediaTek for tailored deployment packages.
5. Practical applications demonstrate their effectiveness, such as rapid spam filtering in Tencent Mobile Manager and improved conversation quality in smart-cabin assistants.
Tencent has unveiled a fresh lineup of compact Hunyuan models: 0.5 billion, 1.8 billion, 4 billion, and 7 billion parameters. These models are designed for low-power and edge deployment. All four versions can now be found on GitHub and Hugging Face and can perform inference using a single consumer-grade graphics card. This makes them ideal for devices with limited resources like laptops, smartphones, and smart-cabin systems.
Impressive Performance
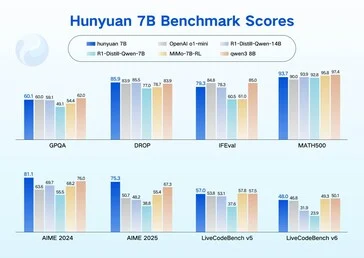
Even though they are small, these models deliver top scores in tasks such as language comprehension, math, and reasoning on various public benchmarks. Tencent credits a unique “fusion reasoning” architecture for these impressive results, which allows users to switch between a quick-response mode for straightforward answers and a slower mode for detailed, multi-step reasoning.
Technical Highlights
A standout feature of these models is their native 256K token context window, capable of processing about 500,000 English words in one go. Tencent points out that their in-house tools like Tencent Meeting and WeChat Reading utilize these models to analyze complete meeting transcripts or entire books at once, preserving character relationships and plot elements for further inquiries.
Integration and Endorsements
The four compact LLMs are compatible with popular inference frameworks, such as SGLang, vLLM, and TensorRT-LLM, and they support a variety of quantization formats. Early support from companies like Arm, Qualcomm, Intel, and MediaTek suggests that deployment packages tailored for their specific processors are on the way.
Practical applications from early users highlight the release’s focus on real-world utility. Tencent Mobile Manager has achieved rapid spam filtering in milliseconds without needing to send data off the device. Additionally, a dual-model approach in Tencent’s smart-cabin assistant optimizes power consumption while enhancing conversation quality. Tencent believes these examples show that smaller models can provide enterprise-level capabilities when designed thoughtfully.
Source:
Link
Leave a Reply