
Google's DeepMind has unveiled a new AI tool capable of generating background music and sound effects for silent videos. This "video-to-audio" system aims to simplify the video editing process, especially for content creators.
Currently under development, this technology offers some intriguing capabilities. Here’s an overview of the process:
User Input
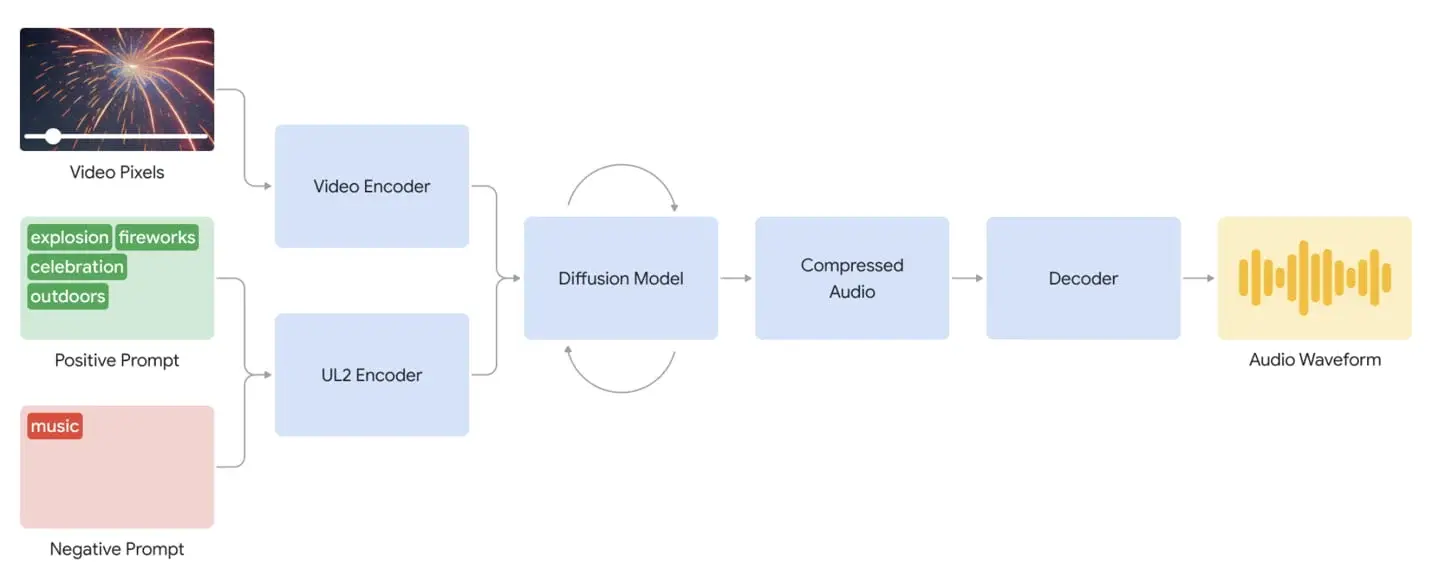
Creators start by uploading their silent video and can include keywords or phrases to guide the AI in producing the appropriate soundscape. For instance, a silent video featuring someone walking in the dark might benefit from prompts such as “movies, horror films, music, tension, footsteps on concrete” to help the AI grasp the mood and context.
AI in Action
DeepMind’s AI model begins by breaking down the video to analyze its visuals. This visual data is then paired with the user-provided text prompts. Through a diffusion model, the AI processes this combined information iteratively, eventually creating background sounds that match the video content.
Tailoring the Soundscape
The model can generate different audio options for a single video, allowing creators to select the best match for their project. DeepMind’s system can also take into account the emotional tone of the prompt words. For example, prompts that emphasize “tension” might produce suspenseful background music, whereas prompts like “joyful celebration” could result in more upbeat sounds.
Looking forward, DeepMind is continuously refining this technology. Future plans include enabling the AI to generate sounds automatically based solely on the video content, eliminating the need for user prompts. Additionally, they aim to enhance the system’s ability to synchronize generated dialogue with the characters’ lip movements in the video.
This "video-to-audio" technology has the potential to transform video editing, particularly for creators who do not have access to professional audio tools or expertise.
Leave a Reply